面试复习
C#
重载与重写的区别
重载是在类内,发生在编译阶段,重写是发生在父子类之间,运行时override,修改了函数表的函数地址
深浅拷贝的区别
浅拷贝是引用,直接指向同一个内存地址,拷贝变量的修改会直接影响到原变量
深拷贝则是值,会构造一个新的内存区域,并把值完全复制过来
值类型和引用类型 / 堆和栈
值类型:int float之类的基础类型加上枚举和结构体
引用类型:数组,类对象,string
区别在于值类型的大小是确定的,被分配在了栈上,而引用类型可以指向任何对象,大小未知,被分配到了堆上
栈是由操作系统分配的空间,存储短期数据块,超出作用域自动释放
堆则需要人工申请和释放,用于存储长期数据,哪怕超出作用域甚至引用丢失了也不会主动释放,C#中依赖于于GC回收
值类型和引用类型可以通过拆装箱来互相转换,但是可能引起内存GC
拆箱和装箱
装箱:堆上分配空间,复制值类型,返回引用
拆箱:先检查,确保给定的obj是一个值类型的装箱对象,将该值复制到栈中
抽象和接口
接口内不能定义字段,可以定义属性和方法,访问权限默认pulibc,接口可以继承接口,接口是引用类型
接口代表某一种行为,抽象类代表某一类对象
访问权限
Public 全局;Private 类内部;Proteced 子类;Internal 本程序集内;Sealed 不可继承/不可重写
静态类
随着类的加载而加载,优先于对象存在,即使没有实例化类也会
不实例化类就可以访问数据和方法,一般用于工具类或者扩展类啥的
反射
用于动态获取类的信息、创建类对象
System.Reflection.Assembly.Load(“XXXX.dll”) 动态加载程序集 System.Type.GetType(“XXXX类名”) 动态获取某程序集中某类信息 System.Activator.CreateInstance(Type type); System.Reflection.MethodInfo method = type.GetMethod(“方法名”) 获得方法 System.Reflection.MethodInfo.Invoke(object , new object[]{参数}) 调用的类实例和实例参数
闭包
| [C#委托与匿名方法内存分配总结 | 仙猫洞 (cathole.top)](http://cathole.top/2021/11/13/delegate-and-lambda-memory-alloc-summary/) |
本质是编辑器会创建一个匿名类
垃圾回收
GC的思路比较简单:
1.将所有堆内存都标记为垃圾
2.将正在使用的内存块标记为有效
3.释放所有没有使用的内存
4.整理堆内存减少内存碎片
但是如果每一次GC都遍历整个内存那开销就太大了,所以C#这边采用了一种分代的思想,假设新分配的内存为0代内存,而经历过1次GC还没有被释放的内存则会变为1代,再之后是2代,原理就是长期存在的内存被GC的可能性很小,而新分配的内存则很可能立刻就需要释放
当0代内存达到阈值后进行一次0代释放,幸存的内存会进入1代,当1代内存达到阈值之后会对1代和0代都进行一次释放,幸存者进入2代,之后也是同理
0代和1代的内存阈值较小,可以很快的释放,而2代的内存大小则根据应用程序确定,释放2代内存时等于一次完整的释放,代价较高
特殊说明,Unity的MONO没有采用分代回收的思想,一次回收就会遍历所有
String和StringBuilder
string是特殊的引用类型,虽然string定义的对象是可以改变的,但并不是直接在原来的内存里改变他的值,不考虑暂存池的情况下,string每一次改变,都会申请
一个新的内存空间,然后再赋值,就会导致很多没有意义的GC
stringbuilder则类似于一个存储着字符的List,他是可以动态扩容改变的,只要你不超出容量,就不会引起新的内存分配,当然超出容量之后还是会和List一样自动
扩容的
字符串暂存池
因为string每一次改变都会引起内存分配,效率很差,因此C#内部存在一个字符串暂存池,本质是一个字典,键是字符串,值是指向某一个具体字符串的引用
当然并不是所有字符串都被会放入这个字典,只有编译阶段的文本字符常量会被自动添加到驻留池,或者通过String.Intern()也可以把字符串放入暂存池
委托和事件
委托,本质上是函数指针
委托必须先用初始化,然后才可以直接+-
事件是对于委托的再高一级封装
事件不能够初始化,只能够+-
匿名对象的内存分配
Action对象赋值(1)=匿名方法赋值(1)>方法名赋值(100)
无闭包(1)=捕获静态字段(1)>捕获实例字段(100)>捕获局部变量(200)
C#委托与匿名方法内存分配总结 - 知乎 (zhihu.com)
List源码分析
本质上还是一个数组,如果只是普通的new一个List,没有其他任何操作,那C#这边默认的大小应该是4,长度为4容量也为4
此时如果我们添加第五个元素,那么容量不够了,就会申请一个新的,两倍容量的数组,也就是8长度的数组,并把原来4个元素拷贝过来,然后插入第5个元素
此时数组的长度是5,容量是8,如果之后又不够了那容量会继续翻倍
问题在于每一次扩容,都会申请一个新的内存,然后旧的数组内存被舍弃,导致GC
删除元素或者Clear都不会物理意义上的增删,只不过是修改了内部的长度,逻辑上告诉你我删掉了,我清空了而已
Dictionary源码分析
字典是一种映射关系,最基本的算法就是哈希映射,也就是哈希表,哈希表的主要问题是哈希碰撞,这是不可避免的,C#这里的解决办法是拉链法,也就是映射
数组并不直接指向目标元素,而是指向一个单链表,将冲突的元素依次存储到单链表里
其余主要操作均和List类似
Hashtable和Dictionary的区别
字典是泛型,而哈希表的key和value都是object,存储时可能存在拆装箱问题
字典是顺序的,哈希表是无序的
NET与Mono的关系
.NET只是一个技术平台,这个平台有一个标准是.NET Standard,.Net Framework/.Net Core/Mono:实现了这个标准、
Lua
深浅拷贝
默认是浅拷贝,深拷贝需要自己实现,方法就是递归拷贝table
Pairs与iPairs
iPair顺序遍历数字key,不连续时结束遍历
Pairs则是无序遍历整个table
什么是UserData
一块内存数据,用于存储特殊的数据结构,但是这块内存的数据的解析与设置需要我们自己实现,Lua只负责内存块的引用和回收
使用xlua时,c#中的class类型与struct类型就会映射为userData
元表
个人理解就是,就像C++重写操作符一样,你想重写table的操作符,就得通过元表实现
father = {
prop1=1
}
father.__index = father -- 把father的__index方法指向它本身
son = {
prop2=1
}
setmetatable(son, father) --把son的metatable设置为father
print (son.prop1)
这里的__index就是元表的一个元方法,当然你还可以重写其他操作符
Lua模拟OOP也是利用这个机制
Lua与C/C++、C#的通讯原理
简单来说,Lua与C/C++之间通信的核心是Lua栈,一种特殊的栈,索引1永远代表栈底,-1永远代表栈顶
当C/C++与Lua通信时,先把需要的参数压入栈,然后Lua侧出栈取出参数,根据参数在Lua计算获得结果,最后再把结果压入栈,C侧在出栈数据
当然C#就没法直接和Lua栈交互了,但是C#可以用P/Invoke吊用DLL中的C方法,所以会比上面的过程多一步
C++
C++是否类型安全?
不是,不同类型的指针可以强制转换
delete/new与malloc/free的区别
malloc/free是c/c++的标准库函数,new/delete是c/c++的操作符。
malloc/free只分配、释放内存,new/delete可以用来创建,释放对象,会自动执行对象的构造函数/析构函数。
智能指针
智能指针是对普通指针的进一步封装,智能指针不是指针,是一个类,其目的为了方便管理堆内存
独占指针,对某一块内存拥有唯一使用权,不能被其他对象复制,析构时自动释放目标内存
共享指针,多个共享指针可以指向同一块内存,所有共享指针内部会有一个指针,指向同一块计数器内存,每多一次共享,计数器就加一,少一份共享 ,计数器就减一,当计数器数量为0时,自动析构目标内存,可以拷贝和赋值,会自动累加引用计数,但是,如果使用两个不同的共享指针对同一块内存初始化,那他们之间的引用计数会各自独立,一旦某一个共享指针的引用计数变为0,就会释放内存,可能导致内存泄漏
弱指针,如果两个对象AB内部都有一个共享指针指向对方,次数两个对象的共享指针引用计数均会是2,导致永远无法正确析构,而弱指针就是为了解决共享指针循环引用的问题,他可以指向一个共享指针,但是不会增加引用计数并且无法直接使用,只是提供了一种访问原指针的途径
多态
多态就是面对同一行为不同对象的不同反应,C++通过虚函数实现了多态
C++的每一个类都存在一个隐藏指针,这个指针指向了一个虚函数表,虚函数表里存放了该类重写的虚函数和新定义的虚函数
假设基类一共有3个虚函数,那么派生类的虚函数表里也会有这3个虚函数,如果派生类重写了虚函数A,那么虚函数表里的虚方法A会被替换为派生类自己重写的方法,如果派生类新加了一个虚函数,那么会添加到虚函数表的末尾
虚函数表
每个包含虚函数的类都维护一个虚函数表,如果A继承B,B包含虚函数,那么即使A本身没有虚函数,他也会有一个虚函数表
class A {
public:
virtual void vfunc1();
virtual void vfunc2();
void func1();
void func2();
private:
int m_data1, m_data2;
};

虚表是一个指针数组,内部是虚函数的指针,编译阶段就已经确定了虚表内的值
虚表属于类,而不属于具体对象,类的所有实例化对象都拥有同一个虚表
当子类重写父类的虚函数时候,虚表对应位置的虚函数指针会发生变化,会指向重写的函数
假设B继承自A,并重写了虚函数fun1

动态绑定,可以通过基类的指针调用子类的虚函数
int main()
{
B bObject;
A *p = & bObject;
p->vfunc1();
}
因为B重写了fun1,此时会调用到重写过后的函数
纯虚函数
即其他语言中的抽象方法
常见内存错误
内存泄漏,在函数中主动申请的堆内存但未释放,多次调用函数可能导致系统内存耗尽
野指针,指向位置内存区域的指针,可能该区域内存已经释放也可能从未初始化,使用这部分内存会导致未知异常
访问越界,访问了超出数组长度的内存区域
返回了指向临时变量的指针
类和对象的区别
对象是类的实例化,类只是定义的一种数据结构
注意,声明类但不实例化同样可能占用内存空间,这取决于类内是否有静态变量
内存分区
栈,由系统自动分配自动回收,一般是临时变量,函数参数等
堆,由程序员主动申请,主动释放,通过new和delete操作
代码区,存放代码
全局静态区,存储全局变量和静态变量
常量存储区,存储常量
全局变量与静态变量的区别
全局变量对所有源文件均有效,静态变量只对当前源文件有效
右值引用和移动语义
int a = 1;
右值就是出现在表达式右边的值,a是左值,1是右值,很明显在表达式结束后右值就不在存在了
但是这样也不够准确,比如你可以int a = b
准确的说法是,如果能对表达式取地址,那么是左值,否则就是右值,我们肯定不能对一个常量取地址
左值引用就是变量的别名,而右值引用不太一样
A getTemp()
{
return A();
}
A && a = getTemp();
此时getTemp返回的是一个右值,a的类型是右值引用,延长了右值的生命周期
移动构造
【转载】右值引用 - Microm - 博客园 (cnblogs.com)
指针和引用的区别
引用必须初始化,指针可以不初始化
引用是别名,指针是地址
当函数传参时,如果是引用传参,则不需要对形参分配存储单元,任何操作都会直接应用在实参上(C# ref)
常量指针、指针常量、常量引用
const之后所指的东西代表常量
int const* p //*p是常量,不能修改p所指向的内容,*在const后,指针常量
int* const p //p是常量,不能修改p的指向,const在*后,常量指针
int const& p // &p是常量,不能修改p的值
注意,没有引用常量
什么时候需要使用常量引用?
使用引用可以提高传参效率,同时如果不希望实参被修改,那就可以使用常量引用
内联函数与宏定义
内联函数可以在编译时直接将函数嵌入到目标代码处,再之后的运行中不会中断调用,但他同样可以做到函数的参数检查
而宏定义则是完完全全的字符串替换,没有内联函数安全
内存对齐
理论上,32位系统中,int占4字节,char占1字节,但如果一个结构体中有1个int和1个char,这个结构体却会是8字节
为什么要内存对齐?因为,虽然内存是以字节为单位,但处理器读取内存是有一定的内存粒度的(比如4字节一读,8字节一读)
STL六大组件
容器,主要就是各种数据结构像是Vector List Deque之类的
分配器,实现内存的分配与释放,分配器是对于malloc的再封装,当申请内存比较大的时候,底层直接就是malloc,对应的就是free
当申请内存很小的时候,如果也这么分配那容易造成内存碎片,因此提供了二级适配器,内部维持了一张内存链表,会从链表中存取数据
算法,各种常用算法,比如常见的排序和查找算法
迭代器,迭代器能够帮助我们以某种方式访问特定的容器,本质是对于指针的再封装,因为并不是每一种容器的内存都是连续的,不能通过简单的加加减减来进行指针的改变,所以每一种容器都有一种针对于她的迭代器,迭代器也有一些不同的类型
适配器、仿函数 了解不多
Vector
对于数组的一种封装,数组的大小在申请内存时就确定了,不能再改变,但是Vector可以,Vector是动态数组,其空间会随着元素的加入自动调整,因为是数组,所以内存是连续的,当空间不够的时候会申请一个新的空间,拷贝旧数据,然后释放就内存,一般来说每次增长是两倍
size、capacity、resize、reserve
size是当前存储的元素个数,capacity代表一共可以存储的元素个数
resize,如果目标大小比原来的大,则多出的元素以默认值填充,如果比原来的小, 则删除多余的元素
reserve,如果目标大小比原来的大,则开辟所需的空间,如果比原来的小,那不进行任何处理
迭代器失效
迭代器的作用就是让使用者可以在不关心数据结构的情况下遍历容器,其底层是对指针的不同分装,甚至vector的迭代器就是一个普通指针,所以vector迭代器失效,意味着指针指向的内存空间失效了,可能是由于扩容,重置大小,等各种原因
List
双向链表
Deque
一种双向开口的特殊数组,虽然感官上是双向开口的连续数组,但逻辑实现上复杂很多,本质上上,先有一个连续数组空间,数组里每一项都是一个Node(理解为链表的Node),然后每一个Node又都指向了一个数组,类似于二维数组,我们所有的操作其实都在第二维度上
UGUI
纹理
纹理大小 = 长x宽x通道数x通道大小
比如128x128的RGBA 32bit,贴图大小 = 128x128x32/8/1024 = 64kb,/8是因为8比特=1字节,/1024是因为1024字节=1KB
默认RGBA32是无压缩,Dithering是一种抖动技术,ETC1和PVRTC4是两种压缩格式,排列组合可以得到一些压缩方案

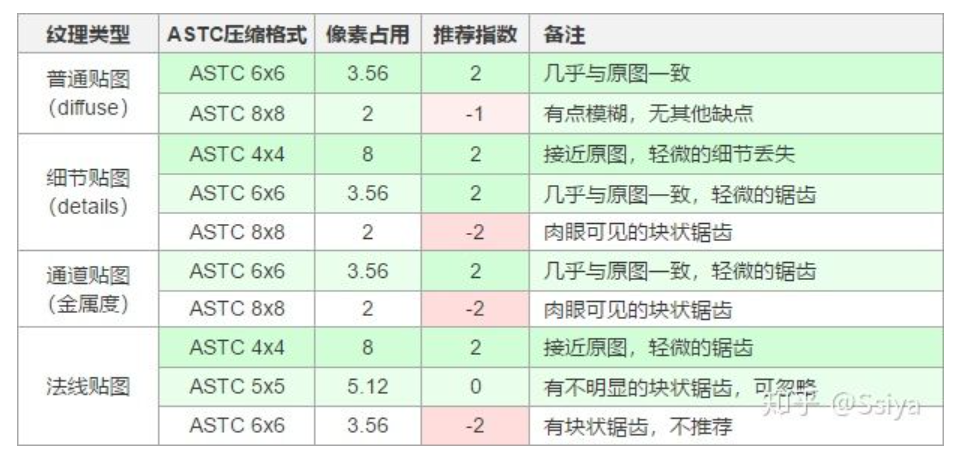
现在无脑使用ASTC压缩
UGUI OverDraw 和 Drawcall
DrawCall
CPU准备好需要绘制的信息,然后提供给GPU,如果每次只提供一组或者一个信息,那会儿导致DrawCall非常多,导致性能问题
OverDraw
指的是GPU对同一片像素区域的重复绘制次数,尽可能减少UI的重叠
DrawCall 合批
通过一定的手段,CPU可以一次性向GPU传入很多组的绘制信息,达到一次DrawCall多个绘制的目的
在UGUI中,合批主要依赖于元素深度,以及元素材质
当一个元素下面没有其他元素时(如果A在B下,那在Hierarchy中A应该在B上)(有没有其他元素,指的是两个元素的mesh部分是否相交),他的深度为0
否则,他的深度就是他下面元素的深度+1
利用这个规则可以得到所有元素的深度排序,然后再看材质,如果相邻元素的材质相同,那么可以合批(图片属于同一个图集,每一个字体算一种材质,默认材质也算一种材质)
UGUI常用优化
- 关闭不需要的Raycast Target
- 纯粹为了点击的空Image改用Empty4Raycast
- 考虑动静分离,经常移动的物体考虑使用子Canvas
- 少用Mask采用Mask2D
- 避免SetActive,设置层级,移动坐标,或者Alpha
- 全屏UI时可以关闭场景相机
图集的作用
-
UI的合批处理
减少DrawCall多张图片需要多次DrawCall,合并成一张大图只需要调用一次DrawCall
-
减少对内存的占用
OpenGL每张贴图都需要设置为2的N次方才能使用,假设有宽高分别为100x100、10x10的两张图片,如果不合成大贴图,那么就需要分别使用128x128和16x16的图片,会浪费一部分内存空间。
如果是使用一张大图的话,就可以将两张图片打到128x128的图集,进而减少内存的占用。
- 提升效率
图片尺寸为2的次幂时,GPU处理起来会快很多,小图不可能做不到每张图都是2的次幂的,但打成一张大图就可以。
Mask和Mask2D的原理
Mask
- Mask会赋予Image一个特殊的材质,这个材质会给Image的每个像素点进行标记,将标记结果存放在一个缓存内(这个缓存叫做 Stencil Buffer)
- 当子级UI进行渲染的时候会去检查这个 Stencil Buffer内的标记,如果当前覆盖的区域存在标记(即该区域在Image的覆盖范围内),进行渲染,否则不渲染
Mask2D
- C#层:找出父物体中所有RectMask2D覆盖区域的交集(FindCullAndClipWorldRect)
- C#层:所有继承MaskGraphic的子物体组件调用方法设置剪裁区域(SetClipRect)传递给Shader
- Shader层:接收到矩形区域_ClipRect,片元着色器中判断像素是否在矩形区域内,不在则透明度设置为0(UnityGet2DClipping )
- Shader层:丢弃掉alpha小于0.001的元素(clip (color.a - 0.001))
Unity
Mono生命周期
比较关键的几个Awake,OnEnable,Start
Start会等所有脚本的Awake执行完成之后再开始执行,每个脚本的Awake执行完之后会立刻调用他自己的OnEnable
然后是FixedUpdate这是在物理层的,物理层最后是Trigger,Collision
然后是游戏层Update,LateUpdate
Start方法并不是重写父类的方法,那么Unity在底层是如何调用到他们的呢?
unity是基于mono的,而mono本身就支持基于字符串查找方法,应该会在运行时注册所有的方法到一起,最终由Mono调用
协程
迭代器与协程 - 旧亚楠 (logarius996.icu)
组件隐藏协程会停止吗? 不会
IL2CPP做了什么?
将IL中间代码编译成了C++代码
AssetBundle.Unload(true/false)
使用true会真真卸载掉,所有AB相关的资源
使用false只会卸载掉那些没有使用的AB资源,正真使用的资源不会被卸载,但会和AB失去关联,下一次加载资源时会重复
ECS
实体,组件,系统
通过紧密排布的内存模型,增加cpu命中率
因为 Cache 是一串一串(Cache Line)的读取的,就是读取某个数据时,会把周围的数据也读取进来,凑成固定的大小(Cache Line)。如果数据存储是连续
的,则很有可能刚好把下次要读取的数据也一起读取进来了。比如数组的遍历。ECS 的内存友好也是因为数据结构是多个连续的数组组成
热更新
算法
KMP算法
常规暴力算法是两个for循环强行匹配,复杂度取决于匹配文本和匹配目标的长度
KMP算法的核心在于Next数组,即利用好每一次匹配失败时的信息,而Next数组的创建只和匹配目标有关,和匹配字符串无关
Next数组本质是一个状态转移二维数组,大小是Nx256,N取决于匹配目标的大小
考虑两种情况
- 如果匹配文本中遇到的字符,与匹配目标当前字符一致,那么状态+1
- 否则退回到最大影子状态,影子状态指的是和当前状态拥有最大前缀的状态
动态规划(与分治法的异同)
动态规划问题思想及算法_z海清的博客-CSDN博客_动态规划算法思想
快速排序
选一个基准数k,从左右两边开始ij一起遍历,比k小的放到k左边,比k大的放到k右边(其实就是交换),直到ij相遇
此时k会在中间,所有比k小的数都在他的左边,所有比k大的数都在他的右边
然后对着两边递归进行上述操作
快排不稳定(指的是相同大小的元素也可能交换位置)
链表相关
- 链表长度:遍历
- 求倒数第N个节点:用两个指针,第一个指针先走N-1步,然后两个指针一起走,当第一个指针走到NULL时,第二个指针就是倒数第N个节点
- 判断链表是否有环:两个指针,一个每次走一步,一个每次走两部,如果他们相遇了,那么就有环
- 链表逆置:至少需要3个临时节点,对应于当前节点,当前节点的前置和后置节点,然后从头开始逆序
其他各种排序
插入、希尔、归并、堆、桶
树
二叉树
每个父节点只有两个子节点
二叉查找树
每个父节点只有两个子节点,同时左孩子都比父节点小,右孩子都比父节点大(可以反过来)
平衡二叉树
在二叉查找树的基础上,任意节点的左右两颗子树最大高度差为1
四种平衡旋转:平衡二叉树 —— 如何优雅的进行旋转 - 英雄哪里出来的文章 - 知乎
图形
| [入门精要 | 01 图形学基础01 - 旧亚楠 (logarius996.icu)](https://www.logarius996.icu/2021/10/09/UnityShader01.html) |